日积月累 - 一些小知识
日积月累 - 一些小知识
这里准备放一些日积月累的小知识,排版等也可能会在后期不断调整归类。
About Github/Git
CHANGELOG.md
更新日志文件,格式可参考:https://www.bestyii.com/topic/75
如何只clone git仓库的一个分支
1 | |
一些命令(学Git)
版本回退
- 当前版本:
HEAD - 上个版本:
HEAD^ - 上上个版本:
HEAD^^ - 上100个版本:
HEAD~100
1 | |
其中:
--hard会强制变成上个版本(工作区暂存区清空)--soft会将相对上一个版本的变化保留到暂存区和工作区(已经add到暂存区过的变化还在暂存区 未add的变化还在工作区)--mixed(默认选项)会将相对上一个版本的变化全部放到工作区。
另一个解释版本:
--hard:完全回退提交,丢弃暂存区和文件的所有修改。--soft:回退提交,但保留文件和暂存区的修改。--mixed:回退提交,丢弃暂存区的修改,但保留文件的修改。
举个例子:
创建一个空的git目录,添加文件1并commit,添加文件2并commit,添加文件3并放到暂存区(git add)。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36mkdir LetGit
cd LetGit
git init
echo 1 > 1
git add 1
git commit -m "1"
echo 2 > 2
git add 2
git commit -m "2"
echo 3 > 3
git add 3
# 文件3不做commit
git log
# commit 0236bc83d4ad4bfc91d3235c732ef7f940d4e5cd (HEAD -> master)
# Author: LetMeFly666 <814114971@qq.com>
# Date: Thu Dec 12 22:04:28 2024 +0800
#
# 2
#
# commit 9878b30ab7cae61d9211962d9ac0aec8e7da434a
# Author: LetMeFly666 <814114971@qq.com>
# Date: Thu Dec 12 22:04:28 2024 +0800
#
# 1
#
git status
# On branch master
# Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# new file: 3这时候,分别在此基础上进行下述三种操作:
git reset --hard HEAD^则已经被commit的2和刚被add到暂存区的3都会被丢弃!(其实丢弃的是
HEAD^之后的“更改”。)
2
3git status
# On branch master
# nothing to commit, working tree clean亦或者:
git reset --soft HEAD^则已经被commit的2和刚被add到暂存区的3都会被放到暂存区
2
3
4
5
6git status
# On branch master
# Changes to be committed:
# (use "git restore --staged <file>..." to unstage)
# new file: 2
# new file: 3使用
git reset --hard 0236b、echo 3 > 3、git add 3命令来恢复到实验开始时的状态,使用--mixed进行测试:
git reset --mixed HEAD^则已经被commit的2和刚被add到暂存区的3都会被放到工作区
2
3
4
5
6
7
8git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
# 2
# 3
#
# nothing added to commit but untracked files present (use "git add" to track)注意Windows系统中
cmd中的^大概是连接符的意思,可以使用git reset --hard "HEAD^"或git reset --hard HEAD"^"或git reset --hard HEAD^^来表示HEAD^。如果有从未跟踪的内容(例如
echo 4 > 4但是不git add),那么无论git reset时传递哪个参数,文件4都会原封不动地躺在工作区(这是因为历史记录中也没有文件4)
查看日志/commit记录
git log查看commit记录
1 | |
会显示历史commit信息,每个commit会显示Author、Date、Message、Merge等很多信息(很多行)。
1 | |
一个commit只显示一行,会显示(其他分支和)commit信息。
1 | |
以图的形式显示分支及合并记录。
git reflog查看引用日志。
假如我使用了git reset回到了历史版本,我如何回来呢?可以git reflog查看回退前的commit id,然后git reset --hard COMMIT_ID。
丢弃工作区/暂存区更改
丢弃工作区更改:
1 | |
丢弃filename在工作区的更改。如果暂存区有此文件的版本则回到暂存区的版本,否则回到版本库的版本。
丢弃暂存区更改:
1 | |
会把filename文件的更改从暂存区回退到工作区。
切换分支
- 创建并切换分支:
git checkout -b NEW_BRANCH或git switch -c NEW_BRANCH - 切换分支:
git checkout BRANCH或git switch NEW_BRANCH
本来切换分支也是git checkout,但是由于checkout和丢弃工作区文件太像了,所以新版本git支持了switch命令
分支合并
TODO: https://liaoxuefeng.com/books/git/branch/policy/index.html#0
CRLF和LF换行符处理
在Linux和Mac中文件的换行符都是LF而在Windows中默认是CRLF。虽然文件看起来没有什么差别,但是在git的时候会发现其实每一行都变了。因此git可以通过配置core.autocrlf来进行一些自定义。
core.autocrlf有三个选项:
true: 提交时会将文件的CRLF转为LF,检出时会将LF转为CRLF。(适合Windows用户)input: 提交时会将文件的CRLF转为LF,检出时不进行转换。(适合Linux/Mac用户)false: 提交和检出时都不进行任何转换。
1 | |
如果想批量将文件中的CRLF转为LF,则可以在Git bash中使用命令:
1 | |
批量转为CRLF:
1 | |
如果经常报错fatal: LF would be replaced by CRLF in xx,则可以将core.safecrlf设置为false。
批量删除空的远端分支
今天在执行git remote -v的时候发现,我有一百多个空的远端分支:
1 | |
这些^remotes/origin/\d{3,4}$的远端分支实际上早已被merge到master后删除。我想批量删除这些空的远端分支,发现了一条命令:
1 | |
执行起来嘎嘎爽。
git status等文件名显示中文
1 | |
已提交历史修改
修改所有提交的username和email
1 | |
github action相关一丢丢
action的.yml一定要放到目录.github/workflows下!不能放在子目录下。
git拉取另一台机器上的代码
1 | |
如果想push,可能要再machine1上执行:
1 | |
About Github GH(Github CLI)
安装:
Mac:
1
2brew install gh
# brew upgrade ghWindows:
Releases点
show all xx asserts,找到GitHub CLI 2.87.2 windows amd64下载并添加到环境变量path中;或者找GitHub CLI 2.87.2 windows amd64 installer傻瓜式下一步安装。
登录:
1 | |
添加project权限:
1 | |
About HTML
空白字符
这是一个空白字符:“ㅤ”
WebView2
(实为Edge内核?)编写的程序可以借助webview2实现网页的访问与浏览。相当于是浏览器。若电脑上安装有WebView2,则程序可以直接借助WebView2实现网页的浏览。
见到一个B站UP主打包WebView2的视频。
canonical
canonical 就是告诉搜索引擎:“这些页面看起来不一样,但你把它们当成同一个页面就行,正主是这个。”
同一篇内容有不同url可能会导致搜索引擎:
- 权重被分散
- 可能被认为是「重复内容」
- SEO 变差
1 | |
HTML全屏幕取色器
Chrome、Edge、Opera浏览器支持EyeDropperAPI,可以将鼠标变成一个取色器,取色器会将鼠标变成一个“圆形放大镜”,用户在屏幕上任意位置(哪怕是浏览器外)点击鼠标左键则HTML可以获取到该位置的颜色RGB,鼠标移动过程中经过像素颜色对HTML不可见。
注意,当前Firefox、Safari浏览器以及所有主流手机浏览器都不支持该API。
体验地址:web.letmefly.xyz。可查看网页源码,不难发现源码很简单。
HTML渲染耗时问题
有这样一个HTML:
1 | |
你猜在M3 Pro芯片的MacBook Pro的Chrome146.0.7680.153浏览器中打开需要多久?答案是平均5秒往上。
这么长一段都在注释中都很慢,所以最佳的方式也许是另外一个文件然后fetch。
但是,好像只在打开本地html时会很慢。
About Linux
Ubuntu防火墙
查看当前防火墙状态:
1 | |
1 | |
开启某个端口并且仅允许单个ip访问:
1 | |
SheBang
shell脚本文件开头的#!,也叫Sha-bang(Sharp bang的缩写),无正式中文名,有时被翻译为释伴(解释伴随行的简称)。
位于文件开头,指定解释器(若无对应解释器则使用默认shell执行)
代码示例
1 | |
运行结果
1 | |
zsh里面 path和PATH是一个
ZSH中修改$path变量也会自动修改$PATH变量。
Linux登录欢迎语motd
使用ssh登录Linux时会显示Linux欢迎语,据不完全测试,修改/etc/motd为你想要显示的内容即可。(比如看板娘)
Linux列出所有中文字体
1 | |
删除一个文件夹中的100万个文件(除了几个特殊文件不删)
假设当前文件夹下有100万个toDel-*文件和4个其他文件。这100万个文件是想要删除的,这4个文件是想要保留的。怎么做?rm toDel-*会提示-bash: /usr/bin/rm: 参数列表过长。
怎么办?借助一个空文件夹使用rsync命令来进行吧:
先创建一个空文件夹mkdir ../tmp,再创建一个文件../toKeep.txt用来写不想要被删除的文件列表。
生成../toKeep.txt的方法之一
可以先将所有文件名排序后导入到一个文件里:ls -lf | sort > ../fileList.txt,
查看文件并将头尾要保留的文件导出到../toKeep.txt中:cat ../fileList.txt | head -4 > ../toKeep.txt、cat ../fileList.txt | tail -2 >> ../toKeep.txt。
最后,使用以下命令即可。
1 | |
命令的含义是:删除./中不在../tmp中的文件,../toKeep.txt中的文件除外。
Linux拷贝文件并显示进度
1 | |
或
1 | |
一行命令在远程Linux服务器上执行命令
其实在ssh登录命令后面加上要执行的命令就可以了。
1 | |
例如我在Linux服务器上有一个具有执行权限的timer.sh,其中内容是:
1 | |
那么我就可以执行以下命令:
1 | |
然后你就可以看到一个进度条,5秒后进度达到100%。
crontab执行导致持续mailto CPU占用率过高
Linux crontab定时任务的stdout和stderr会默认发送“邮件”到mailto配置的用户,在我服务器隔三差五在crontab执行前后报CPU使用率过高的警报后,我守在了一次crontab任务执行前,使用htop检测CPU使用率较高的进程。
到达指定时间后,先是定时任务占据了一下高CPU,然后CPU利用率很快就下去了。后面就出现了mailTo进程,/bin/bash /usr/sbin/sendmail -FCronDaemon -i -odi -oem -oi -t -f root,持续占据较高CPU。
解决办法:crontab -e并在头部加上个
1 | |
就好了。
如果想只针对某些特定任务设置不sendmail也可以修改crontab的命令并加上> /dev/null 2>&1。
Linux通过挂载实现“创建文件夹的只读视图”
假设我Linux服务器上有一个文件夹如/xx/xx/x/很深的路径/x/xx/sync/Codes,这个文件夹会自动同步代码,我有两个需求:
- Linux服务器是被动同步代码的地方,不是主动修改代码的地方,只负责编译代码并运行,尽量不要不小心改到代码
- 默认的同步路径太深了,且为同步路径,不适合作为程序的执行路径
所以有没有办法在/xx/Codes创建一个文件夹“只读视图”呢?
在
/xx/Codes文件夹下,所有文件和/xx/xx/x/很深的路径/x/xx/sync/Codes相同,同步脚本对/xx/xx/x/很深的路径/x/xx/sync/Codes的修改也会作用到/xx/Codes上,且/xx/Codes文件夹中的内容没有写入权限,只能读取。
试试挂载吧!只需要执行:
1 | |
就可以了。
第一条命令是在“绑定挂载”,第二条命令是在“重新挂载已绑定的/xx/Codes目录,并修改其挂载属性为只读”。
这样源文件夹/xx/xx/x/很深的路径/x/xx/sync/Codes属性不变,可被同步脚本正常读写;目标文件夹/xx/Codes内的所有文件都只读,因为这是一个Read-only file system。
Linux在用户尝试使用ssh登录时显示欢迎语
/etc/ssh/sshd_config中加一行:1
Banner /etc/ssh/let_banner.txt将你想要在ssh连接时显示的“欢迎语”写入
/etc/ssh/let_banner.txt1
echo "Welcome, you idiot." | sudo tee /etc/ssh/let_banner.txt > /dev/null(可选)重启sshd服务
1
sudo systemctl restart sshd
这样,别人(其实是所有人,包括你自己)在进行ssh登录你的Linux主机时,身份验证前都会先看到一句:
1 | |
About Mac
SMB协议时不生成.DS_Store
禁止Finder浏览SMB文件夹时生成.DS_Store:
1 | |
删除已在SMB文件夹中生成的.DS_Store:
1 | |
可能需要重启系统或Finder才能生效
1 | |
Cmd+Space突然无法检索本地应用之Spotlight索引重建
不知是iCloud过期还是为何,最近Command+空格突然无法检索到本地应用,例如我输入个iTerm会出来“照片中1个结果”等等但就是没有我要找的应用。
于是:
1 | |
重建一下关于应用的索引,差不多好了。
About Windows
Windows应用商店安装的应用
Windows应用商店安装的应用似乎不一定能找到.exe文件。那么这些应用到底安装到了哪里呢?
1 | |
例如胡桃工具箱1.4.1.0_x64_Test的安装位置是:C:\Program Files\WindowsApps\7f0db578-026f-4e0b-a75b-d5d06bb0a74d_1.4.1.0_x64__7jfyf5536hdrr
Windows沙盒复制文件时发生错误的原因
有时候在Windows Sandbox中下载了一个4G的学习资料,将其复制到主机时,可能会遇到复制了一半突然
1 | |
然后如果文件复制时不干其他事情,只让系统进行复制操作,基本上每次都能复制完成且不出错(我没遇到过这样还报错的)
某天(应该是2023.2.24),突然就发现了这“未知错误”的原因
如果我们在主机和沙盒间通过复制粘贴的方式传输文件时,在文件传输过程中,我们又复制了其他东西,那么这时候文件传输就会出现上述错误!只要我们不更新剪贴板,随意操作其他东西,我是没见过复制错误发生未知错误的情况。
我想,也许其原理是通过剪贴板的看不见的“文件链路”进行传输的?
autohotkey
记录一下autohotkey,它是一款是一款免费的、Windows平台下开放源代码的热键脚本语言
官网:https://www.autohotkey.com/
Bat中获取bat文件所在目录
在.bat文件中,%~dp0代表所执行bat所在的路径。
我们在C:\BatDir\test.bat中写入以下代码:
1 | |
然后在F:\CWD目录下使用cmd执行上述bat文件:
1 | |
则会echo "%~dp0"会显示C:\BatDir\;explorer "%~dp0"会打开资源管理器,且位置是C:\BatDir\;cd /d "%~dp0"则会使CMD的工作路径变成C:\BatDir\
Windows安装或卸载程序失败时的修复程序
安装外星人AWCC(Alienware Command Center)后暴力删除残留文件了,导致卸载和重装AWCC时都失败。
因此发现了一款微软官方的修复程序:修复阻止程序安装或删除的问题,可下载MicrosoftProgram_Install_and_Uninstall.meta.diagcab并运行。(自解压程序)
Windows禁用某些Win开头的快捷键
今日按快捷键Ctrl+C,不小心按成了Win+C,弹出了Cortana,还告诉我说“你的语言不可用”。???
想要禁用快捷键Win+C,需要在注册表HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced下新建一个“字符串值”,名为DisabledHotkeys,值为C。(若想禁用Win+C和Win+S,则值为CS)
重启计算机或重启资源管理器即可生效。
UPX加壳减小可执行文件体积
UPX官网upx.github.io,主要目的是将可执行文件和共享库(通常是二进制文件)压缩为更小的尺寸,从而减少磁盘占用空间和下载时间。
Pyinstaller打包可执行文件时若系统变量里有upx,则打包出来的体积也会小一些。
Win10右下角托盘区时间显示到秒
Win + R -> regedit -> 回车,定位到计算机\HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced并新建DWORD (32位)值(D),名为ShowSecondsInSystemClock值为1,重启explorer.exe。
PowerShell修改文件日期
1 | |
PowerShell生成uuid
1 | |
1 | |
WOL(Wake on LAN)网络唤醒
归类到Windows下其实并不仅局限于Windows。
- 固件支持WOL
- 局域网或公网可达
- 网卡有待机电
- 接收到魔术网络包(Magic Packet),内容
6 字节的 FF+目标网卡 MAC 地址 × 16 次
没有认证,知道Mac地址就能发。
About Phone
Phone APP 如视VR
记录一款软件,使用智能手机拍摄就能三维建模。智能手机拍摄将信息传到服务器上,云计算后返回,可在线浏览。免费,但不可下载模型。
其视频讲解可见:科技宅小明的视频科技还是魔法?!2分钟重建我的家!
早点有的话就能多建模两个地方喽~
About Python
Python chain
连接两个iterable的东西为一个iterable的东西
1 | |
执行结果:
1 | |
Python bisect
python二分查找用。
bisect.bisect_right(list, val)类似于C++的upper_bound(list.begin(), lise.end(), val) - list.begin()
同理,bisect_left类似于lower_bound
Python json.dumps
格式化输出json(实质是将python字典转化为格式化后的字符串)
1 | |
运行结果:
1 | |
其中ensure_ascii默认为True,这时会以ASCII码的形式输出(中文你好就变成了”\u4f60\u597d”)
More:json.dumps是将字典转为字符串,json.loads是将字符串转为字典。假如从爬虫得到的返回值是json格式的字符串,想将其格式化后输出,那么就可以:
1 | |
运行结果:
1 | |
Python enumerate
python的enumerate可以将可迭代的“iterable”,打包成(index, value)的tuple:
1 | |
运行结果:
1 | |
Python双端队列 deque
1 | |
Python优先队列 heapq
Python优先队列小元素先出队(小根堆)。
1 | |
Python sortedcontainers.SortedSet
Python有序集合,类似C++的set
但缺点是需要手动安装,非Python自带
1 | |
1 | |
Python有序集合SortedList
类似于C++的multiset。
1 | |
Python selenium踩坑记录
Python的selenium可以控制浏览器对网站进行模拟操作,但需要注意的地方有且不仅仅有如下二:
- 执行js脚本时:
1
2
3
4
5
6
7function ha() {console.log("666")}
ha()
报错 未定义
ha = function() {console.log("666")}
ha()
正常执行 - selenium4.0之后移除了find_element(s)_by_xx的方法(#2),需要使用find_element(s)_by方法。
Python 依赖分析工具
写了一个Python项目准备发布,那不得写一个requirements.txt来告诉使用者都需要安装哪些第三方库?
手动添加是一种方法。另外一种方法就是使用依赖分析工具pipreqs。
1 | |
静态类型检查工具mypy
根据你声明的类型自动检查你变量的实际类型是否相符。
1 | |
1 | |
Python asyncio
async是Python 3.5引入的一种用于处理一步编程的特性,通过协程来实现,能够一定程度上避免阻塞。
1 | |
- 程序会先执行
first函数中的print("first begin"),执行到asyncio.sleep(1)时这个操作会暂停协程1秒,在等待期间时间循环可以切换到其他协程继续执行。 - 此时
second函数中的print("second begin")会被执行,然后执行asyncio.sleep(2)暂停2秒,且在此期间事件循环可以执行其他任务。 first函数的1秒等待完成后,执行print("first end"),协程执行完毕。second函数的2秒等待完成后,执行print("second end"),协程执行完毕。- 两个协程都执行完毕,程序结束。
运行结果:
1 | |
但是,只有手动让出控制权的操作才会避免阻塞循环事件,例如asyncio.sleep()、asyncio.open()、asyncio.connect()等。普通的文件读写、网络请求仍然会阻塞进程。
Python版本切换pyenv
安装:
1 | |
然后在.zshrc中添加:
1 | |
列举所有python版本的命令是pyenv versions,但我想让它是pyenv list,那么就可以:
1 | |
相当于创建一个~/.pyenv/plugins/custom/bin/pyenv-list文件,当执行pyenv list时,就会调用这个文件,这个文件执行pyenv versions。
类似的还有:
1 | |
About C++
C++原地建堆make_heap
1 | |
C++使得编译器支持第三方库(以MinGW为例)
假如我想使用EasyX库编写带有图形界面的程序,那么我应该如何编译呢?
可以把EasyX解压出来的.h头文件放到{MinGW安装位置}\x86_64-w64-mingw32\include,库文件放到{MinGW安装位置}\x86_64-w64-mingw32\lib目录。
这样就能直接#include <graphics.h>了。编译时候需要加上参数-leasyx,这是因为添加了libeasyx.a。
如果我把库文件放到其他目录下,则还需要加上-L目录名(绝对路径或编译执行路径的相对路径)。
About Java
Java 有序集合 TreeSet
类似C++的set。
1 | |
Java 数组操作 Arrays
包含一些对数组的“排序”、“填充”、“判等”等操作。
1 | |
About Golang
Golang数组(array)和切片(slice)
数组定长切片变长,数组是值类型(数组赋值给另一个数组会复制整个数组)切片是引用类型(切片赋值给另一个切片时两切片会指向同一个底层数组)。
1 | |
About Rust
VsCode rust-analyzer插件分析crate变量类型
较大项目中VsCode插件对于其他crate中的变量类型默认可能不会解析,例如let s = FastStr::new("hi"),当我们输入s.的时候,VsCode的rust-analyzer插件可能并不会有补全提醒,甚至我们输入s.no66666666().hi111111VsCode也不会有任何反应。
这体验很不好,没有语法检查和补全提醒就快变成一个支持高亮的记事本了。在settings.json中添加以下两行可以令rust-analyzer插件分析补全提示其他crate。
1 | |
About Website
ip扫描工具censys
很多网站为了防止DDos等都使用CDN等将自己的真实ip隐藏起来。但是如果直接访问真实ip的话,还是有可能会返回SSL证书(例如浏览器提示的“证书无效/不匹配”
censys扫描全球所有IP并记录ip与域名直接的关系,并且扫描速度快得惊人(>_<)
网址:censys.io
域名收集工具/SSL证书查询工具crt.sh
网址:crt.sh,传说所有的SSL证书都能在上面查到(好像是)
并且,输入一个域名,它的所有子域名甚至都能被查到(似乎前提是开了https)。
hexo部署到子路径上
在_config.yml中令url的值为/x.com/sub/path。
否则不这么配置的话很多链接会链接到/x.com/
ngxin获取cloudflare后的真实ip
使用cloudflare获取网站流量后打到网站的ip都是cloudflare的。若是使用nginx分发的这些请求,则可以通过下面两步获取真实ip。
- 判断nginx是否支持real_ip功能(若无则此教程无效,似乎要重新编译nginx):
nginx -V 2>&1 | grep -i http_realip_module。若有(可能被标记为红色)则进入下一步。 - 编辑conf文件,在
http下添加几行:其中1
2
3
4
5
6http {
set_real_ip_from 173.245.48.0/20;
set_real_ip_from ......;
real_ip_header X-Forwarded-For;
}set_real_ip_from的数据可以由https://www.cloudflare.com/ips-v4和v6版本获得。
参考链接:dmesg.app、blog.gezi.men、CSDN
nginx自动寻找.html后缀的文件
例如我有一个hello.html,我希望用户访问hello路径时候就能得到这个html而非一定要访问hello.html路径的话,可以:
1 | |
certbot自动颁发TLS证书
Let’s Encrypt提供免费的TLS证书以辅助站长实现https上网。
以CentOS为例:
安装certbot
1 | |
certbot安装证书
一行命令搞定,从域名归属权认定到nginx.conf修改均自动完成
1 | |
首次要输入email。
管理证书列表
1 | |
续期
1 | |
读《大型网站技术架构——核心原理与案例分析(李智慧)》有感
- 当一台服务器的处理能力、存储空间不足时,不要企图去换更强大的服务器,对于大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求。这种情况下,更恰当的做法是增加一台服务器分担原有服务器的访问及存储压力。
- 网站的价值在于它能为用户提供什么价值,在于网站能做什么,而不在于它是怎么做的。所以在网站还很小的时候就去追求网站的架构师舍本逐末,得不偿失的 。
- 在业务问题还没有理清楚的时候就从外面挖来许多技术高手,仿照成功的互联网平台打造技术平台,这无疑是南辕北辙,缘木求鱼。而这些技术高手离开了他们熟悉的环境和工作模式,也是张飞拿着绣花针使不上劲来。
- 虽然分层的架构模式最初的目的是规划软件清晰的逻辑结构便于开发维护,但在网站的发展过程中,分层结构对网站支持高并发向分布式方向发展至关重要。因此在网站规模还很小的时候就应该采用分层的架构,这样将来网站做大时才能有更好地应对。
About API
bilibili API
bilibili数据查询API:能得到JSON格式的某个BV视频的播放点赞等数据
1 | |
例如
1 | |
About AI
About PyTorch
torch.cuda.empty_cache()
使用torch.cuda.empty_cache()命令可以清除nvidia显卡中一些已经不使用的显存。在我的一个实验中,它能将显存降个十几个G。
为什么nviDia要使用这么多的额外空间呢?D君这么做一定有他的道理。
以下是来自ChatGPT的解释:
1 | |
About ChatGPT
让ChatGPT模拟派蒙
1 | |
About Codex
Codex session存放位置
1 | |
1 | |
About Office
Word公式 - 部分居右
Word中经常需要插入一些公式,但是很多时候需要在公式的最右边标注(1-1)类似的内容。这就涉及到了公式的部分居右显示。
怎么实现呢?首先是编写一个公式(插入 -> 公式),接着编写完成后,在后面输入#(1-1)并回车,就可以看到#后面的(1-1)已经居右显示啦。
Word查找缺失字体
前几周写本子的时候,打开Word一看,这表格咋这么怪呢?非得在下一页多一行。后来才知道原来是缺少字体的原因。
查看所缺少的字体的方法:文件-选项-高级-字体替换,所列出的字体都是“因没有这种字体所以Word找了一个类似的字体用来替换”。
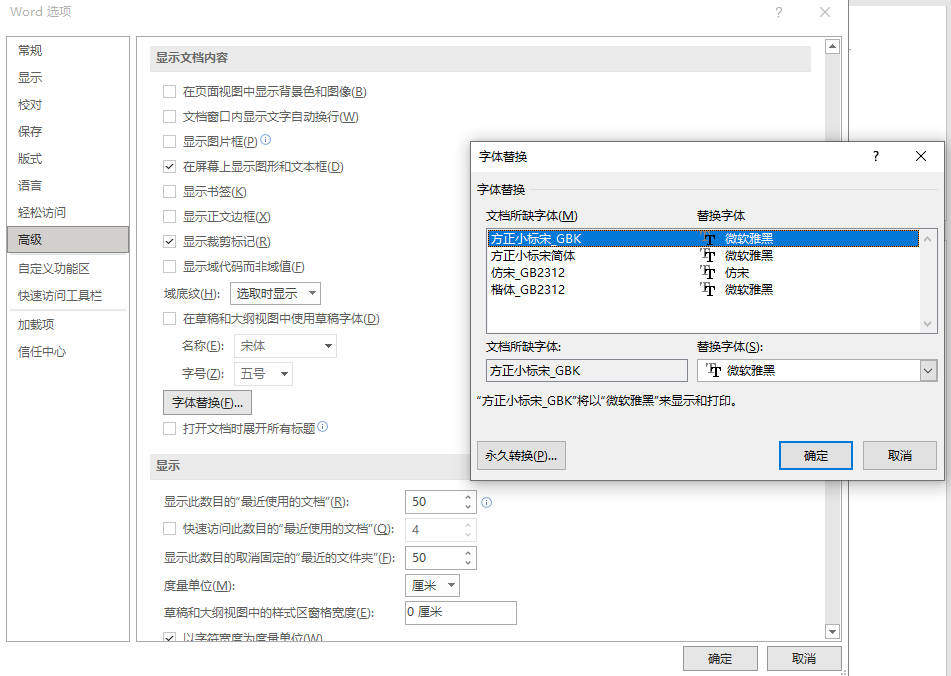
依次从网上下载所有缺失的字体并安装到系统上。
下载完所有缺失的字体,重新打开Word,显示就正常了。
About Technology
非视域成像
以墙为镜,利用激光在墙面上的漫反射,推算出不可直接看到的区域的图像。
About Latex
Ubuntu上安装Latex(免安装版)
我想使用sudo aptitude install texlive-full命令安装xelatex但是失败了。于是想到了直接下载可执行文件并添加到环境变量的方法。
首先下载TeX Live 安装脚本,然后解压并安装。
1 | |
根据提示直接安装(不用修改配置)就行。
最终输出(提示)
1 | |
根据它的提示将三个内容分别添加到三个环境变量中,并重启终端即可。
1 | |
About 俚语
Best-Effort
不保证质量,只保证“我尽力了”。
例如UDP不保证一定成功。
Noisy Neighbor
同一台大机器上的别人太猛,把自己拖累了。
如:
- 多个用户共享同一物理资源,某个用户磁盘狂写
- 实验室有人用迅雷下载
Breaking Change
不向后兼容的变更
例如:
1 | |
用户一升级版本,代码就炸了。
End
同步发文于CSDN,原创不易,转载请附上原文链接哦~
https://blog.letmefly.xyz/2023/02/21/Other-Accumulation-SomeTips